Dr. Mario Alberto Diaz Torres
El doctor Mario Alberto Diaz Torres cuenta con una maestría en probabilidad y estadística por el Centro de Investigación en Matemáticas (CIMAT) en México. Además, obtuvo su grado de doctor en matemáticas y estadística por la Queen's University en Canadá, y un doctorado por la Arizona State University en conjunto con la Universidad de Harvard donde trabajó en la teoría matemática y estadística de la privacidad de datos. También cuenta con un posdoctorado en el CIMAT donde trabajó en la teoría matemática y estadística de la privacidad de datos y matrices aleatorias. Actualmente es investigador asociado en el Instituto de investigaciones en matemáticas aplicadas y en sistema de la UNAM. Sus intereses de investigación son privacidad de datos, teoría de la información y aprendizaje máquina teórico.
Privacidad desde una perspectiva de Teoría de la Información
04/marzo/2022 Seminario PISIS-UANL 2022 Asistencia : *
Introducción
Se tiene una muestra de los datos del censo de Estados Unidos de 1994, y se quiere diseñar un clasificador que tomará algunos atributos de personas como edad, educación, ocupación y género; para predecir la categoría de ingresos (mencionada como income bracket) menor de 50,000 mil dólares al año y más de 50,000 mil al año. Este es un problema central en machine learning y en esta charla, se presenta una metodología para abordar el problema.
Resumen
Antes de empezar las charla se nos comparten algunos conceptos necesarios para entender la metodología: la exactitud del clasificador, que es una medida empírica de la exactitud de predecir si el sujeto cae en el ingreso esperado. La auditación del modelo es un proceso que revela sesgo contra algún grupo y puede ser detectado por inspección visual, experimento contrafactual e inspección de coeficientes (revisar los coeficientes de la regresión lineal para cada variable e identificar aquel que muestra una desproporción con los demás coeficientes). Clasificación de equidad es una manera rápida de lidiar con un problema de equidad y consiste en eliminar el coeficiente que muestra un sesgo. Costo de equidad es la modificación a la equidad la cual tiene típicamente un costo a la exactitud del modelo de predicción.
Como práctica estándar, antes de iniciar el proceso de aprendizaje es necesario preprocesar los datos obtenidos para su mejor tratamiento en la metodología. El atributo de edad el cual está registrado en el rango 17 a 90, normalizamos y aplicamos una transformación de tal manera que tenemos ahora un rango de 0 a 1. El atributo educación tiene 16 posibles valores yendo desde preescolar hasta doctorado denotado como x15 donde x es un número comprendido entre el rango (0,...,15). El atributo ocupación es un vector de 14 diferentes ocupaciones, cada uno tratado como un atributo binario, por ejemplo (1,0,0,...,0) o (0,1,...,0,0) o (0,0,...,0,1). El atributo género es una variable binaria en el que se asigna 1 si el individuo es mujer y 0 si es hombre.
La función de clasificación h la obtenemos por un ajuste de mínimos cuadrados, Se define la función h la cual mapea de un vector de 16 posibles respuestas a un conjunto {1,0} donde 1 es la predicción de que un individuo tenga un ingreso de mas de 50 mil dólares y 0 de otra manera.
Conclusiones
En esta plática se logró dar a conocer uno de los problemas centrales en machine learning, el cual consiste en cómo poder medir y destruir una base de datos por relación entre diferentes variables. Las aplicaciones mencionadas de este trabajo van relacionadas directamente al mundo financiero y legal, en donde tenemos como ejemplos los modelos matemáticos que deciden aprobar o rechazar un crédito bancario. Otro ejemplo que se menciona es que puede ser usado para calcular qué tan probable es que un ex-convicto reincida por un crimen, siendo un dato importante en estos modelos las métricas que se utilizan para la exactitud de los modelos.
Algunos inconvenientes que surgieron dentro de esta investigación fueron encontrar sesgo para ciertos grupos de la base de datos, los cuales se resolvieron mediante auditaciones del modelo. Finalmente se estableció que no es suficiente eliminar solo una variable, ya que algunas variables del atributo están muy correlacionadas,por lo tanto se puede utilizar un atributo parcialmente, en el que solo se puede perder un porcentaje de exactitud para estar en los estándares requeridos.
Enlaces relevantes
Reseñas anteriores
Comunicación de la ciencia
En esta primera sesión , los profesores del Posgrado en Ingeniería de Sistemas, Dr. Arturo Berrones y Dra. Elisa Schaeffer, conversan sobre sus percepciones sobre la importancia y las formas que toma la comunicación de la ciencia. Nos compartirán su perspectiva de cómo ésta ha evolucionado, primero con la globalización y la tecnología, y más recientemente por retos actuales como la pandemia de COVID-19.
Leer
Sesgos en la web
En esta sesión el Dr. Ricardo Baeza-Yates aborda el tema del sesgo en los datos en la web, haciendo énfasis en el contexto de los sistemas de búsqueda y recomendación, así como la importancia de reducir el mismo.
Leer
De investigación académica a ciencia de datos empresarial
En esta sección el M.C. José A. Hernández Saldaña comentará sobre las diferencias entre la investigación académica y la empresarial en el área de ciencia de datos.
Leer
Robustez en la red óptica chilena
En esta sesión el Dr. Javier Bustos Jiménez presentará un estudio sobre la robustez de la red óptica chilena y los resultados del mismo.
Leer
Selección de cartera de proyectos
En esta sesión la Dra. Nancy Maribel Arratia Martínez platicará sobre el caso de selección de cartera de proyectos con información imprecisa, tratada mediante números difusos.
Leer
Detección de pre-micro ARNs con CNNs
En esta sesión el M.C. Jorge A. Cordero Cruz comentara sobre las ventajas de la detención de los micro-ARN con el uso de Redes Neuronales Convolucionales (CNNs). Los micro-ARN son microrreguladores de la expresión génica en una gran variedad de tipos celulares y procesos fisiológicos, lo que los convierte en buenos candidatos para su uso como biomarcadores.
Leer
Marca de agua digital
En esta sesión el Ing. Víctor Briones comentara sobre la marca de agua digital, sus usos e importancia.
Leer
Gestión de equipos como ingeniero de software
En esta sesión el M.C. Saúl Gausin Valle, comentará sobre el trabajo en equipo, gestión eficiente e importancia del mismo desde la perspectiva de la Ingeniería de software.
Leer
Vida después del posgrado
En esta sesión el Dr. Luis A. Benavides Vázquez comentará sobre las oportunidades y retos que se pueden presentar al concluir un posgrado, así como algunos consejos para enfrentar el cambio que esto supone.
Leer
Incentivo en la teoría de control
En esta sesión el Dr. Manuel Jiménez discutirá el concepto básico del incentivo en un juego donde existe una jerarquía de dos niveles.
Leer
Paseos aleatorios
En esta sesión el Dr. Francisco Javier Almaguer Martínez comentará sobre los paseos aleatorios, lo que estos pueden modelar y algunos aspectos teóricos y prácticos de problemas relacionados con los mismos.
Leer
Autómatas celulares para análisis de datos
En esta sesión la M.C. Astrid González Leyva comentará sobre diferentes variantes de autómatas empleados para análisis de datos, aplicaciones, ventajas y desventajas de los mismos.
Leer
Un problema de localización e inventario
En esta sesión la Dra. Nelly Monserrat Hernández González comentará sobre un problema de localización de instalaciones considerando el inventario en éstas. Además, mostrará la formulación matemática del problema, las técnicas de solución utilizadas y la robustez de las soluciones obtenidas.
Leer
Uso de inteligencia computacional para resolver problemas altamente dimensionales
En esta sesión el Dr. Gregorio Toscano Pulido presentará una introducción al tema de la inteligencia computacional, los paradigmas asociados, así como problemas altamente dimensionales. Además, mostrará datos de interés sobre los grandes volúmenes de información que se generan actualmente cada segundo.
Leer
Distributing Live Video over the Internet
In this session Mr. Logan Hanks will comment about the protocol HTTP Live Streaming (HLS). How does it work, and how does it design affects the experience of live interactive events?
Leer
Evaluaciones multi-método en el contexto de la Psicología Clínica
En esta sesión la Esp. Daniela Escobedo Belloc comentará sobre las evaluaciones multi-método en el contexto de la Psicología Clínica y ejemplificará este enfoque a través de diferentes instrumentos aplicados a casos clínicos.
Leer
Retos éticos en la inteligencia artificial
En esta sesión los doctores Elisa Schaeffer, Romeo Sánchez y Arturo Berrones debatirán sobre los retos actuales de la Inteligencia Artificial (IA) desde una perspectiva de ética. Además, comentarán sobre las limitaciones de la IA, así como posibles soluciones a futuro de las mismas.
Leer
Ciencia de Datos, Apoyo a la Decisión Multicriterio e Investigación de Operaciones en Industria 4.0
En esta sesión el Dr. Fernando López Irarragorri comentará sobre la utilización de técnicas de ciencia de datos, ciencia de la decisión (Apoyo a la Decisión Multicriterio) e investigación de operaciones como parte de una propuesta metodológica de apoyo a la toma de decisiones para enfrentar problemas que surgen en el marco de la industria 4.0.
Leer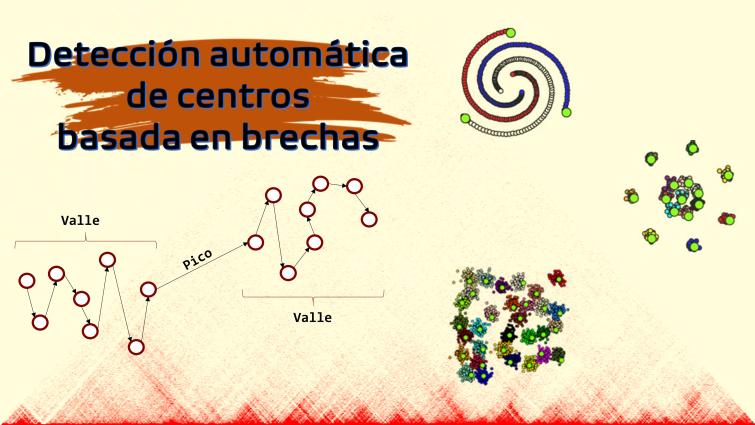
Agrupamiento de picos de densidad con detección automática de centros basada en brechas
En esta sesión la Dra. Sara Elena Garza Villarreal comentará sobre una propuesta, en la cual combina la herramienta Clustering basado en densidad con la detección automática de centros basada en brechas. Además muestra cómo se puede obtener agrupamientos de calidad y también predecir el número de grupos con exactitud mediante esta técnica.
Leer
Formulación de la optimización no-lineal y del aprendizaje de máquina como sistemas desordenados
En esta sesión el Dr. Arturo Berrones comentará sobre la combinación del aprendizaje automático y la programación matemática, mediante una reformulación de los problemas de optimización (no-lineal y combinatoria) y del aprendizaje de máquina como sistemas desordenados.
Leer
Actividad económica en tiempo real: estandarización de documentos tributarios electrónicos
En esta sesión el M.C. Dagoberto Ramón Quevedo Orozco presentará una metodología de estandarización y utilización de la utilización de los documentos tributarios electrónicos para el seguimiento de la actividad económica en Chile, con la utilización de aprendizaje automático supervisado e ingeniería de datos.
Leer
Problema de programación y dimensionamiento de lotes en la producción de inyección de moldes
En esta sesión la Dra. Yasmín Águeda Ríos Solís presentará una heurística iterativa de dos etapas basada en programación matemática para la solución de un Problema de programación y dimensionamiento de lotes en la producción de inyección de moldes.
Leer
We materials engineers suffer of simulation illiteracy, maybe you can help
In this session the Ph.D. Moisés Hinojosa Rivera will comment about the importance and need for collaboration about simulation, with researchers and students in the areas of computer science and software engineering, given the inexperience of materials engineers in this field.
Leer
ML/AI in real life: how to get value instead of getting academic exercise
In this session, the M.Sc. Kirsi Louhelainen will comment about the problems that arise when taking Artificial Intelligence (AI) and Machine Learning (ML) prototypes to the real world.
Leer
From Partial Plans Refinements to Parallel Search Diversification: Exploring Ideas
In this session, the Ph.D. Romeo Sánchez Nigenda will comment about the interconnections between Partial-Order Planning Algorithms (POP) annealing heuristics and parallel best-first search planning and discuss ideas on how these heuristics are used to diversify parallel search.
Leer
Las ciencias computacionales aplicadas a la resolución de problemas en el sector agropecuario
En esta sesión la Dra. Tania Turrubiates López comentará sobre las problemáticas que aquejan al sector agropecuario y como se pueden enfrentar con la aplicación de los conocimientos de las ciencias computacionales.
Leer
Gestión y preservación de datos digitales para investigadores y estudiantes de posgrado
En esta sesión el Lic. Dagoberto Salas Zendejo comentará sobre la importancia de una buena gestión y preservación de los datos de investigación. Además, dará algunas recomendaciones esenciales en dicha gestión de datos.
Leer
The digitalization policy in Finland: case AI and the European struggle
In this session, Ilona Lundström, D. Sc. will comment about the steps that Finland has been taking to accelerate the introduction of artificial intelligence and the digitization of industries. To this end, is implemented a policy plan appropriate to the characteristics of the country.
Leer
Openair: Un caso de estudio de la calidad del aire en Monterrey
En esta sesión el M.C. Jair Rafael Carrillo Ávila comentará sobre el creciente interés hacia la contaminación atmosférica en Monterrey. Además, mostrará a través de un ejemplo con datos tomados del SIMA el alcance de la librería "Openair" de R como herramienta para manipulación, análisis y visualización de datos asociados a la contaminación.
Leer
Académicos en la industria: mitos y realidades del cambio
En esta sesión la Dra. Nancy Aracely Arellano Arriaga comentará sobre la vida del estudiante después de acabar un doctorado, tocando temas como el cambio de la academia a la industria, así como consejos a la hora de buscar empleo.
Leer
Algoritmos de estimación de distribuciones aplicados a la zonificación de parcelas agrícolas
En esta sesión el Dr. Jonás Velasco Álvarez presentará una nueva metodología, que se basa en los algoritmos de estimación de distribución aplicados en la zonificación de parcelas agrícolas.
Leer
Modelación e inferencia de eventos estresantes con modelos no homogéneos de Poisson multivariados
En esta sesión la Dra. Lilia Leticia Ramírez Ramírez presentará una descripción de los procesos de Hawkes y como fueron aplicados en la modelación de ocurrencias de eventos estresantes en la vida de las personas. Además, explicará el método de inferencia propuesto, basado en técnicas estadísticos-computacionales.
Leer
La composición de un aporte científico relevante
En esta sesión una mesa redonda compuesta por la Dra. Satu Elisa Schaeffer (actual presidenta de la comisión de admisiones al doctorado del PISIS) , el M.C. Gerardo Palafox Castillo, el M.C. José Alberto Benavides Vázquez y la M.C. Beatriz Alejandra García Ramos (actualmente doctorantes en del programa) comentará sobre el proceso de admisión, así como las experiencias de los ponentes a la hora de argumentar aportación científica de su trabajo de tesis.
Leer
El rol de la simulación en la Sociedad 5.0
En esta sesión una panel compuesto por los doctores Satu Elisa Schaeffer, Sara Verónica Rodríguez Sánchez y César Emilio Villarreal Rodríguez discutirán sobre el papel que desempeñara la simulación en la nueva sociedad llamada Sociedad 5.0.
Leer
A solution algorithm for the integration of Vehicle Routing Problems
In this section, the Ph.D. Diana Lucía Huerta Muñoz will comment about a solution method based on a Kernel Search matheuristic for the Vehicle Routing Problem (VRP).
Leer
Implantación de un modelo eficiente de programación diaria
En esta sesión el Dr. Andrés Ramos Galán repasará los cuatro aspectos relevantes para la implantación de un modelo eficiente de programación diaria que puede ser utilizado para la gestión real de un sistema eléctrico de gran tamaño.
Leer
La brecha de género en Ciencia y Tecnología
En esta sesión la Dra. Marcela Quiroz Castellanos comentarán sobre la brecha de genero existente en el campo de la Ciencia y Tecnología, abordando las dificultades que enfrentan las mujeres para sobresalir en estas áreas, así como el costo social de esta brecha.
Leer
Criptomonedas, la Web 3.0 y el futuro
En esta sesión el Lic. José Luis González Flores abordará el tema de las criptomonedas y la Web 3.0 explicando conceptos generales, plataformas actuales y áreas de oportunidad.
Leer
Multidisciplinariedad: El trabajo en equipo y su operatividad
En esta sesión los doctores Patricia Liliana Cerda Pérez y José Gregorio Alvarado comentarán sobre la importancia del trabajo en equipo y la estrategia multidisciplinaria, la cual nos permite atacar un problema aunado conocimientos y enfoques de diferentes disciplinas.
Leer
La brecha de género en Ciencia y Tecnología
En esta sesión la Dra. Marcela Quiroz Castellanos comentarán sobre la brecha de genero existente en el campo de la Ciencia y Tecnología, abordando las dificultades que enfrentan las mujeres para sobresalir en estas áreas, así como el costo social de esta brecha.
Leer
Modelos matemáticos de apoyo a la toma de decisiones (reducción de efectos por pandemia de COVID–19)
En la sesión Modelos matemáticos de soporte a la toma de decisiones para la reducción del impacto socio-económico de la epidemia de COVID-19 la Dra. Laura Cruz Reyes Compeán presentará un sistema inteligente de apoyo a la decisión desarrollado para realizar estudios epidemiológicos que soporten los esfuerzos por mitigar los efectos de la pandemia por COVID–19 en México.
Leer
Mantenimiento predictivo utilizando técnicas de inteligencia artificial
En esta sesión la Dra. María Guadalupe Villarreal Marroquín comentarán sobre el uso de técnicas de inteligencia artificial para el mantenimiento predictivo de máquinas industriales.
Leer
IA para el bien social— Reconocimiento de reciclables para mejorar la circularidad
En esta sesión el Dr. Dexmont Alejandro Peña Carrillo comentará sobre el uso de Inteligencia Artificial para mejorar la calidad del reciclaje de materiales y hacer más fácil su adopción.
Leer
Retos de la transferencia de tecnología desde la perspectiva universitaria
En esta sesión la Dra. Elizabeth Solís Pérez comentará sobre los retos de la transferencia de tecnología que enfrentan las universidades para la innovación, el desarrollo tecnológico y la comercialización del conocimiento.
Leer
Felicidad y calidad de vida
En esta sesión la Dr. José de Jesús García Vega comentarán sobre la importancia de enfocar todos los recursos de la humanidad a la generación de felicidad, basándose en la premisa que mientras más personas felices en el mundo hará del mismo un mejor lugar para vivir.
Leer
Reflexiones sobre el Internet de las Cosas
En esta sesión el Ing. Hugo Jesús Vargas Hernández comentarán sobre el Internet de las Cosas, además contextualizará las aplicaciones y mitos de este desde el punto de vista de la educación.
Leer
Amoníaco, ciencia e historia: Fritz Haber y el punto de ebullición de la moral
En esta sesión el Dr. Víctor Manuel Cázares Lira analizará la vida y obra del químico alemán Fritz Haber y su legado en la formación ética de la ciencia moderna.
Leer
Networked Federated Multitask Learning
In this section Alexander Helmut Jung, Ph.D. will discuss recent methods for distributed learning of personalized "tailored" models for local datasets.
Leer
Problemas de diseño de rutas centrados en el cliente
En esta sesión la Dra. Iris Abril Martínez Salazar comentará la estructura y característica de algunos de los problemas clásicos de ruteo de vehículos centrados en el cliente.
Leer
Mejora de la calidad de la energía mediante filtros de energía activos
En esta sesión el Dr. David Juvencio Ríos Soria comentará sobre como mejorar la calidad de la energía eléctrica con el uso de Filtros Activos (APF)
Leer
Supercómputo y big data en astronomía
En esta sesión el Dr. Carlos Esteban Chávez Pech comentará sobre el empleo de Supercómputo y Big Data en Astronomía, dando una introducción histórica al problema. Además, hablará de las demandas pasadas, actuales y futuras de la Astronomía en el Big Data, de un problema en específico.
Leer
Riesgos naturales y el software
En esta sesión el Lic. Gonzalo Astroza Hurtado comentará sobre los mapas de peligro e introducirá diversas herramientas computacionales, modelos y técnicas actuales empleadas en la confección de estos mapas con énfasis en herramientas orientadas al riesgo volcánico.
Leer
Un Recocido Simulado hibridado con Programación Lineal para el problema de impresión de portadas
En esta sesión el Dr. Federico Alonso Pecina propondrá un Recocido Simulado hibridado con Programación Lineal para el problema de impresión de portadas, presente en la industria editorial.
Leer
Modelos de imputación equivalentes para el manejo de datos faltantes en bases de datos
En esta sesión el Dr. Guillermo Santamaria Bonfil comentará sobre técnicas y modelos de imputación equivalentes para el manejo de datos faltantes en bases de datos. Además, presentará el uso de técnicas de aprendizaje automático en la imputación de valores faltantes de concentración en yacimientos geotérmicos.
Leer
La Salud Pública en la otra cara de la pandemia
En esta sesión la Dra. Nataly Mercado Cárdenas y el Ing. José Vargas Díaz comentarán sobre la colaboración entre especialistas médicos y equipos de tecnología de la información en la mejora de la transferencia de información entre los agentes que participan en los distintos procesos de atención en la salud pública en tiempos de pandemia.
Leer
La Matemática en la industria
En esta sesión el Dr. Rafael Muñoz Sánchez comentará sobre temas relacionados con la matemática aplicada en la industria, partiendo de su experiencia dentro de la empresa Aleph5.
Leer